Learning Sanskrit from home:Youtube Channel for Sanskrit Classes
I have already posted several articles about mobile application for learning sanskrit. Some times, some people might feel uncomfortable with mobile because of screen size or any other reason. I have found several wonderful videos in youtube and the author of those mobile apps is same for these youtube videos.
Find several series of classes to learn sanskrit through youtube videos. The author has done wonderful job, they are teaching sanskrit basics with series of classes on Vibhakti and most importantly they are teaching sanskrit through Yoga and Tinantaprakriya . These videos helps you to learn sanskrit from home.
Learning Sanskrit from home: The Best Mobile app for Learning Sanskrit
After investigating a lot finally I figured out one of the best mobile app for learning sanskrit. I have my own analysis for saying this as Best Mobile app, let me explain about it, Vyoma Linguistic Labs has released series of mobile applications and each mobile application has a rich content, innovative techniques of learning sanskrit, most importantly the content is framed keeping value based education in mind. The sanskrit learning apps helps you to learn sanskrit at home.
Learning Sanskrit From Home
There are various options for learning Sanskrit from home, Youtube Channels, Mobile Apps, online classes
Android and iOS Mobile application for Learning Sanskrit : For Beginners
As I already explained in my previous post : For beginners we have an app to learn sanskrit वर्णमाला (varnamala)
Android and iOS mobile application for Learning Sanskrit : For Kids
If you are interested to teach Sanskrit for your kid then the best way to learn Sanskrit for kids is to start with Rhymes and Stories in Sanskrit. It is really great thinking, Rhymes in Sanskrit helps kids to enjoy the learning and stories will impart values along with learning Sanskrit. Your kid will enjoy this mobile app :
Android and iOS mobile application for Learning Sanskrit : Good Sayings/Subhashitaas
In this modern age certainly we have forgotten all good sayings, proverbs and subhashitaas. Well learning such good sayings in sanskrit, subhashitaas in sanskrit is really great.
Android and iOS mobile application for Learning Sanskrit : Nursery rhymes in Sanskrit
This is another Mobile application for nursery kids to learn sanskrit, A collection of nursery rhymes in Sanskrit for little ones to join in with. Its a great way to learn sanskrit rhymes
To learn any language, we have to start with vowels and consonants, in sanskrit collectively they are called as वर्णमाला (varnamala). Let me list out all वर्णमाला of sanskrit here.
स्वर (Svara)
अ आ इ ई उ ऊ ऋ ॠ लृ ॡ ए ऐ ओ औ अं अः
व्यञ्जन (Vyanjana)
कण्ठय Gutturals
क्
ख्
ग्
घ्
ङ्
तालव्य Palatals
च्
छ्
ज्
झ्
ञ्
मूर्धन्य Linguals
ट्
ठ्
ड्
ढ्
ण्
दन्तय Dentals
त्
थ्
द्
ध्
न्
ओष्ठय Labials
प्
फ्
ब्
भ्
म्
अन्तःस्थ Semi Vowel
य्
र्
ल्
व्
Sibilant
श्
ष्
स्
Aspirate
ह्
In sanskrit the most important thing is the way we pronounce the characters, also there is more to learn about these वर्णमाला (varnamala).
Pure स्वर (svara) (vowels) in sanskrita are of two types Short Vowels and Long Vowels, and the pure vyanjanas ( consonants ) are represented with a halant symbol (्) . Still there are lot more to learn about अनुस्वारः (Anusvara) and विसर्गः (visarga).
So this is the starting point for learning Sanskrit. I request to download following android mobile application which will be the starting point for learning sanskrit. These mobile applications helps you to learn sanskrit at home.
Android and iOS mobile Application for Sanskrit Learning For Beginners
Sanskrit is called as a perfect language, an unambiguous language and hence NASA preferred it for Artificial Intelligence. But why so ? How it is different from any other language in the world? Why it is called as a most scientific language? What is so unique in sanskrit language ?
To answer all the above questions, we have to really look into the vyakarana in sanskrit. Though I don’t have enough knowledge in sanskrit, I am writing these articles after exploring a little bit about sanskrit with the help of few online courses of sanskrit ( Vyoma Linguistic Labs :Learn Sanskrit From home )
Vyakarana in Sanskrit:
In english if I say ‘Read‘ it is a just a word and you can not give any more explanation for that, is there any logic behind formation of this word ? Is there any explanation for the word ‘Read‘ or ‘Reading‘ ? Definitely we don’t have any answer for this question.
In sanskrit there is nothing which has no explanation, there is a logic behind formation of each and every word. Let me take simple example
There is a word ‘पठति‘ in sanskrit, which means ‘Read‘ but as I said above for every word there is an explanation, let us see how this word formed
Hope these simple examples help us to understand how rich the sanskrit language is. All I am trying to tell here is learn sanskrit, we have plenty of online courses, videos, mobile applications but I prefer the following pointers because these mobile apps for sanskrit are really very nice.
Being a Bharatiya, I am proud to write this article on sanskrit, Swami Vivekananda said one day “Bharat Mata would be Jagat Guru”, how true it is ! We taught to the world how to speak, we taught to the world how to write, our Vedas,upanishads has references to most of the modern scientific inventions, We knew solar system, galaxies thousands of years ago and what not ?. Every Indian is proud about what our country has given to the world.
I must say the best thing among all our contribution is sanskrit, There is lot lot to know about sanskrit, I just started learning and I am enjoying. I thought to share my understanding and importance of sanskrit in couple of articles.
How old Sanskrit is ?
Vedic sanskrit is being the oldest, dating back to as early as the early second millennium BCE. This qualifies Rigvedic Sanskrit as the oldest. Classical Sanskrit is the standard register as laid out in the grammar of Pāṇini, around the fourth century BCE.
Interesting Facts About Sanskrit Language:
Improvements in Concentration Level : learning sanskrit and speaking in sanskrit language improves our concentration level, If we take current generation, our kids has concentration of maximum 3min – 4min. But study has revealed that (an experiment conducted by Vyoma Labs Banglore ) a student learning sanskrit and speaking in sanskrit has gained concentration level upto 15min – 20min.
As Medicine : Research has proven that probability of Alzheimer disease is less if sanskrit is being used for speaking.
If English language has 25million words, sanskrit has 105million+ words, in fact lots and lots of Vedic scriptures have lost due to many reasons, so we can not give exact number.
Sanskrit is not just a plain language like any other language, it is logical and mathematics involved within it Example : Just see how the words in sanskrit are formed, it is called as vyakarana (व्याकरणम्) .
NASA looking at sanskrit for their work on artificial intelligence – (Ref : NASAKnowledge Representation in Sanskrit and Artificial Intelligence)
There is evidence that Pāṇini’s work in this area influenced modern linguists like de Saussure and Chomsky.
Well the list continues and I am still collecting lot of data on sanskrit, but don’t you think these interesting points motivate you to start learning sanskrit ?
Definitely it is great to find a very good Guru to learn sanskrit, but you can quickly start your learning sanskrit using these mobile apps and video links. Currently I felt these sanskrit learning mobile applications are really great for me to start.
You definitely might have used Google Maps, Whatsapp location sharing feature and any other location sharing mobile application, yeah definitely its a cool feature in smart phones and hence they are so called smart ? 🙂
but there is a man behind these popular GPS enabled devices who made it , Sanjai Kohli an Indian who worked on Mass Market GPS system, he is called as Father Of Mass Market GPS.
US Defense and Work on GPS
Sanjai started working in aerospace companies after completing his masters in US, during that time he was assigned a task where he suppose to add intelligence in bombs dropped from planes, in 1980’s 90 % of the bombs hit the unintended targets, Sanjai worked on a guided GPS systems, He and his team successfully completed the assigned task and all the US military weapons used the technology.
Sanjai Kohli
in 1993 GPS was being used in Tokyo to navigate in Cars, but because of many issues they never use to work properly, Sanjai started working on it and to make it commercialize. He setup a company SiRF by seeing the great opportunities, they reinvented the signal processing physics to reduce the cost and size.and increase power, resulting in tens of thousands of dollars of signal processing/communication equipment to reside in a single silicon chip. The chip was 200 times more capable than those used in the Japanese cars and was available at a fraction of the cost.” with SiRF. And the rest as they say is history. By 2006, 80% of GPS devices ran on SiRF chips. At its peak SiRF had a market capitalization of $3 billion.
With his great work, Kohli has been short-listed for the European Inventor Award (to be announced on April 28) instituted by the European Patent Office and the European Commission.
Sanjay Kohli has two patents
1. Multipath processing for GPS receivershttp://www.google.co.in/patents/US20030165186
ABSTRACT
A GPS receiver system determines the presence of trackable signals at code delays less than the prompt delay being tracked for a particular signal and changes the prompt delay to correspond to the smallest code delay having a trackable signal. Trackable signals at large code delays are multipath signals and may be separately tracked to aid in dead reckoning. The trackable signals at code delays not adjacent to the current tracked prompt delay may be tracked in the same channel as the prompt delay so that all satellite channels are continuously evaluated for multipath signals being tracked or a non-satellite specific channel may be used to sequentially step through the satellite signals to evaluate multipath on a satellite by satellite basis.
2. GPS Car navigation Systemhttps://www.google.com/patents/US6041280
ABSTRACT
A GPS car navigation system derives GPS position update information from motion of the car along the actual track. Turns along the track are detected when they actually occur and are compared with the predicted turns so that the time and position at the actual turn can be used to update the then current GPS derived position of the vehicle. Updating position information with actual turn data improves the accuracy of GPS navigation especially during single satellite navigation.
History of Airplane : Indian invented Airplane well before Wright Brothers
Well the history should be rewritten it is not the Wright brothers who invented airplane, airplane was invented in India thousands of years ago and it was Shivkar Bapuji Talpade who actually flown an unmanned airplane in 1895
Vaimānika Śāstra was distilled from Rigveda. Talpade stayed in Dukkar Wadi ( now named as Vijay Wadi ) Chira Bazar, Mumbai. He was a scholar in Sanskrit Literature and Vedas. Talpade flown his airplane in 1895 and his plane was named ad Marutsakhā.
Maharshi Bharadwaaja attained mastery over the Vedas by studying works of earlier Aachaaryaas, he has presented his knowledge to mankind in his work named ‘Yantrasarvasva’. In the fourtieth chapter he deals with the science of aeronautics. He explained the construction and use of many kinds of aerplanes in 8 chapters, containing 100 subjects heads , comprising 500 sutras.
Bharadwaaja defines the word Vimaana as :
Vega-Saamyaat Vimaano Andajaanaam. Sootra 1
“Owing to similarity of speed with birds, it is named Vimaana.”
In ‘Yantrasarvasva‘ it was given as follows, In order to provide electric force to all parts of the vimaana and make them operate smoothly the Shakti-panjara-keela yantra is to be installed.
“Charging of all parts of vimaana with electric current the Shakti-panjara-keela is made as follows.
Steel, crownchika alloy, and iron, in the proportion of 10,8, and 9, to be powdered and filled in crucible and placed in aatapa furnace and heated to 100 degrees and charded with 10 degrees of electric current, will yield Shakti-garbha metal with whcih the yantra is to be made.
Soorya Shaktyapakarshana Yantra or Solar Heat extracting Yantra
“In order to protect from the cold of the 4 winter months the solar heat storing machine is now explained. The 27th kind of mirror capable of capturing solar heat is to be used in its making.”
It is said in Darpana prakarana: Sphatika or alum, manjula or madder root, sea-foam, sarja salt or nation, sand, mercury, garada or aconite, kishora or wild liquorice, gandhaka or sulphur brimstone, karbura or yellow orpiment, praanakshaara or ammonium chloride, in the proportion of 12, 1, 5, 1, 13, 12, 8, I0, 27, 4, 3, 7, 8, 5, 1. 5, 8, 3, 9, 2, purified, to be filled in antarmukha crucible, placing it in shuka-mukha furnace, and boded. Then pour it into antarmukha yantra or vessel and turn the churning key. When cooled in the mould a fine, light, strong, golden. coloured, solar heat collecting glass will be formed.
Read more interesting Ancient Indian Science and Mathematics
Jira : The basic use of jira tool is to track the issue and to track bugs related to software and mobile application. and user for Project management. Jira is complete solution for project management provided by atlassian. Confluence is the one place for all the team work, Create , Organize and discuss work with your team.
Jira work flow: Configuring Workflow
Jira provides a default workflow which looks like below
jira-defaultworkflow
Open.
Assign.
Resolved.
Reopen.
Closed.
Open: Test Engineer test the application according to the requirement, while testing if test engineer find any issues, test engineer can raise the issue and change the status as open.
Assign: Test Engineer assign a issue to the developer present in the company to fix the issue and change the status as Assign.
Resolved: Developer can check the issue and fix the issue occurred in the application or software and change the status as resolved.
Reopen: Test Engineer retest the application to check whether the issue is really fixed by developer or not and if issue is not fixed test engineer can change the status as reopen.
Closed: Test Engineer retest the software or application to check the issue was fixed by developer or not and if issue was fixed change the status as closed.
How to report bug in Jira tool
Project: In project drop down select a project which we have to test.
Issue type:
Task
Bug
Epic
Story
Task: Task that needs to be done.
Bug: A problem which impairs or prevents the functions of the product.
Epic: An Epic captures a large body of work. It is essentially a larger user story that can be broken down into a number of smaller stories.
Story: Story is user requirement.
Summary: In summary field enter the brief description about the issue or bug.
Reporter: Reporter is a test engineer or a person who is analyzing, finding and reporting a bug or issue.
Components: Components are sub-sections of a project. They are used to group issues within a project into smaller parts. Application contains several components like for example take gmail application,which contain login component and compose component. if user mention particular component where the issue is occurred,its easy to find issue.
Description: Description contains steps to reproduce an issue or bug. And steps of scenario.
Example: steps to validate login button.
Enter Username.
Enter Password.
Click on Login button
Fix/Versions:
Priority levels in Jira:
Highest: This problem will block progress.
High: Serious problem that could block progress.
Medium: Has the potential to affect progress.
Low: Minor problem or easily worked around.
Lowest: Trivial problem with little or no impact on progress.
Labels:
Attachments: Anattachment is any file that is included with your page. Examples of attachments are screenshots, photographs, other images, Word documents, presentations, PDF documents.
Linked Issues:
Issue: Select issue type, issue is either functional or integration or UI issue (User Interface).
Assignee: Assignee is a developer or person who is fixing a issue.
Epic Link:
Sprint: Time taken to complete a project is called as sprint.
Pythagorean Theorem In Ancient Indian Mathematics : Baudhāyana Sulbasūtra
Many great mathematicians have born in Bharat several thousands of years ago, Ancient Indians invented several theorems in mathematics. Aryabhata the Indian Mathematical Genius lived in (476–550 CE) he worked on approximation of pi() and concluded that its irrational, he has given the formula for the area of a triangle, he discussed the concept of sine etc.
But I would like to discuss one of the most popular theorem Pythagorean theorem, it is named as Pythagorean theorem but it was proved by Ancient Indian Mathematicians several hundreds of years before even Pythagoras born. Just look into the sutra given below.
Install an android mobile application to learn more such interesting facts :Download
dīrghachatursrasyākṣaṇayā rajjuḥ pārśvamānī, tiryagmānī, cha yatpṛthagbhūte kurutastadubhayāṅ karoti.
इसका अर्थ है, किसी आयात का कर्ण क्षेत्रफल में उतना ही होता है, जितना कि उसकी लम्बाई और चौड़ाई होती है। ” बोधायन ” ने ” शुल्ब-सूत्र ” में यह सिद्धान्त दिया है।
A rope stretched along the length of the diagonal produces an area which the vertical and horizontal sides make together
Find out best realtime examples, interesting facts on concepts and all the formulas. The best mobile application for 10+ students (PUC I and II year students)









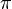 ) and concluded that its irrational, he has given the formula for the area of a triangle, he discussed the concept of sine etc.
) and concluded that its irrational, he has given the formula for the area of a triangle, he discussed the concept of sine etc.
