The most important step in any big application development life cycle is database design, If it requires any data storage. We have come across many developers who will never think much before finalising the database design. Some people will simply add fields into the table , some people simply define the data type without considering the type of data stored in real time. Let’s take a simple example and do analysis which shows big picture of database design importance with small set of data.
Consider the following example , a database designed for a simple requirement and then the analysis of the same.
Example – Requirement
Design a database for a web application where registered users will post articles. Any one can post any article, each article might fall under some category, A Category is again defined under a department and a stream. There will be Maximum 100 departments and 100 streams in the system.
For example , an article on “ Analysis of computer simulated data on wheels of a plane “, this article might fall under “Aerospace” Department, Physics stream .
Another article on “ Calculation of Voltage variations within the cooling system “ ,this article might fall under “Aerospace” Department , Electrical stream.
If we consider the above requirement and two examples , the following design sounds good – ( Note the database designed here is simple and just taken for simple analysis )

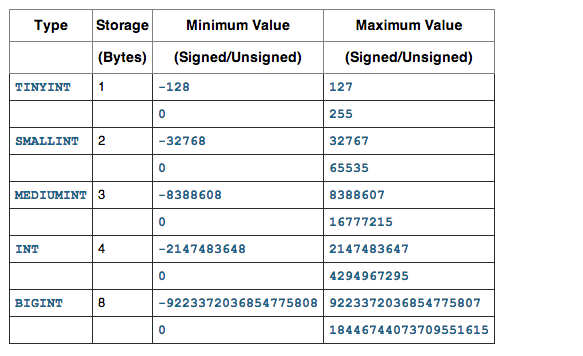
Considering the above design, and observe the department Id and Stream id fields in respective tables are defined as INT , The values of these two fields will never go beyond 100 as per the requirement. The first mistake is the datatype defined INT is not right. It can be declared as TINYINT(1) which holds value upto +127 , since both department id and stream id are declared as INT , extra 3 bytes is wasted for each record, because INT takes 4 bytes, and TINYINT takes 1 byte memory.
Let us analyse this scenario with simple real time example –
Analysis I –
If by chance each table ( department and stream ) holds 100 rows , then considering above storage details of each data type , for each row 3 bytes is wasted and hence if there are 100 records , for each table 300 bytes of data wasted.
So overall 600 bytes wasted from these two tables for just 100 records. This doesn’t make any difference because it is just a matter of few hundred bytes.
But If I change the above ArticePost table as follows ( that kind of mistakes usually happens when the database is bigger which will be having 100+ tables , since here only few tables are there then there is very less chance of such mistakes ).
Analysis II –
Modified ArticlePost table

For a quick access if I put both department id and stream id in ArticlePost table itself , the things will go worse !
Now consider 100 articles for each department and for each stream then total number of rows in ArticlePost = 10 * 100 * 100 = 100,000 articles, this is a simple math total ArticlePosts = (Articles for one dept/stream) * number of dept * number of streams
If we consider 100,000 number of rows in articles then the things will be worse ! For each row 600 bytes of memory waste as per Analysis I , so now for 100,000 rows how much memory waste ?
100,000 * 600 = 600,00,000 bytes = 57.220 MB memory wasted.
In real time , 100,000 of rows is not a big one , We should consider one thing very seriously here , 57.220 MB memory waste just because of two extra fields in a table and with improper usage of datatype .
Have a look on Data types and storage capacity from Mysql official documentation

Update –
Just observe how the data types in RDBMS are , INT(4) , INT(10), VARCHAR(25)
in general INT(N) , where N decides how much space it should consume ?.
Remember what we studied in C ? Can we relate this to C bit fields concept ?
Assume that I wanted to hold a status of the request in ma C program written for managing a government office complaint management system.
struct complaintStatus{
int isComplaintRaised;
int isComplainReceived;
int isComplaintResolved;
} status;
Since We are holding only status , it not required to have an int of 4 bytes ! only one byte is sufficient to hold either 0 or 1 , where 0 indicates NO , 1 indicates YES.
Let me modify the above Struct
struct complaintStatus{
int isComplaintRaised : 1;
int isComplainReceived : 1;
int isComplaintResolved : 1;
} status;
By above structure your compiler will restrict the amount of memory used by status .