
Listen to Silence, It heals – Art

We all knew what is an endianess in computer architectures , the big endian and little endian architectures works different. Big endian where most significant bit stored at smallest address where as in little endian least significant bit stored at smallest address.
The world’s most popular processor Intel is little endian machine, where world’s most oldest motorola processors are all big endian. All the network protocols , routers works in big endian architecture.
Most of the time endianess doesn’t come into picture , because programmers doesn’t deal with very low level bits. Ideally when I say int number = 4; the program runs properly in both kind of architecture. The reason is when the value is processed , it will be always in processor registers, not directly into memory. Endianess comes into picture when we deal with memory bits.
For example – If we are applying some effects or transform on an image by using shift operators or some standard APIs, then the things might go wrong. OpenGL APIs internally deal with shifting the bits in memory to perform certain operations in such cases the entire image may look inverted.
The common convention followed in networking is big endian , all TCP/IP protocols and other network protocols deal with big endian data. Those who work on networking should be aware of endianness.
Let us take an example how endianness might be a problematic
Assume that a System 1 is sending an ip address to System 2 , If system 1 is 80×86 processor which is a little endian and System2 is SPARC machine which is a big endian. An ip address 192.168.2.1 sent from System 1 , will be received by SPARC machine and converts it to big endian format.
If I consider 192.168.2.1 , let us convert this to Hex value
ip address to Hex a logic = take each octet , multiply it by 256 ^ n, where n is zero based index
= (1 * 256 ^ 0) + (2 * 256 ^ 1) + ( 168 * 256 ^ 2) + (192 * 256 ^ 3)
= 1 + 512 + 11010048 + 3221225472
= 3232236033 ( decimal )
= C0A80201 ( Hex )
System 1 is sending value C0 A8 02 01 , but System 2 will interpret it as 01 02 A8 C0
This kind of issues happens due to endianness.
It is always difficult to choose one over the other , but recursive and iterative methods can be chosen wisely by analysing the algorithm with certain input values. Let us study the usage of recursive methods and let us analyse how recursive call works internally.
[AdSense-B]
How Recursion Works ?
The concept of stack frame comes into picture when we deal with recursion, for each call a stack frame will be created and the values will be pushed into stack. Once the recursive call reach the final condition, the program will start popping out from the stack frame and returns the values . A C program to find factorial of given number and analyse it using recursive method.
Let us take an example –
Finding Factorial of a Number
long int count = 1;
long int factorial(long int n){
count++;//to count how many times the method getting called
if (n == 0) {
return 1;
}
return n * factorial(n - 1);
}
int main(int argc, const char * argv[])
{
int n = 13;
printf("Factorial of %d = %lu , number of time called %lu\n",n,factorial(n),count);
return 0;
}
[AdSense-A]
Let Analyse how it works ?
When factorial(n) will be called every time , a stack frame will be created and the call will be pushed to stack, the entire call stack looks like below. The below image shows stack operations for a given recursive call.
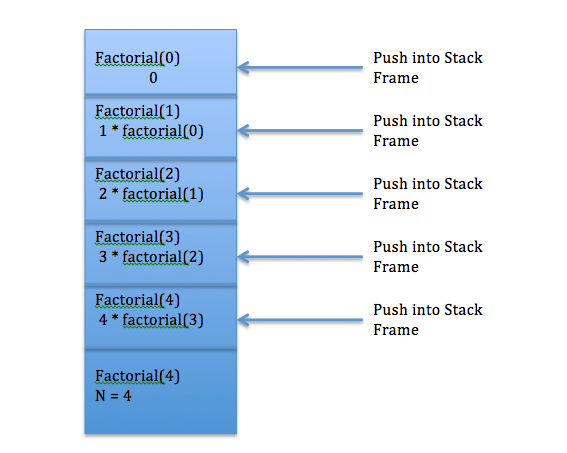
If I give input as 10, the recursive method will be called 12 times,
If I give input as 14, the recursive method will be called 16 times,
If I generalise the number time of call then it will be – n + 2 times.
This looks ok, but let us take different example and try to compare both. A program to find fibonacci number and analyse it with respect to call stack.
Finding Fibonacci number
long int count = 1;
long int fibonacci(int n){
count++;
if (n <= 1) {
return n;
}else{
return fibonacci(n-1) + fibonacci(n - 2);
}
}
long int fibonacciIteration(int n) {
int x = 0, y = 1, z = 1;
for (int i = 0; i < n; i++) {
x = y;
y = z;
z = x + y;
}
return x;
}
int main(int argc, const char * argv[])
{
int n = 4;
printf("fib value recursive %lu ",fibonacci(n));
n = 100; // let us give 100 as input for iterative method
printf("\nIterative method %lu ",fibonacciIteration(100));
printf("\nnumber of time called %lu\n",count);
return 0;
}
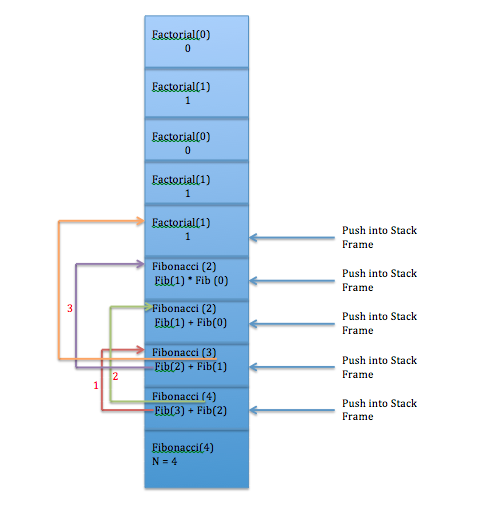
Now the call stack looks as follows, memory layout of call stack for a given recursive call of fibonacci program.

Let us analyse this example ,
If we observe the callstack , fib(2) , Fib(1) and Fib(0) called multiple times, which is not necessary as the value will be calculated .
For input n = 4 , the total number of times the fibonacci method called = 10.
Now let us take few more inputs and check how many times the function is getting called.
n = 5 => 16 times,
n = 6 => 26 times ,
If I generalise the number of time the function called will give us an astonishing result ,
number of times fib function calls = (2^n – C), Where C is constant, and very less ~ 2^n
Let us take some interesting inputs 🙂
n = 30 => 2692538 times
n = 31 => 4356618 times (just by increasing n by 1 , the number of times function called became so huge)
n = 42 => 866988874 times , Unbelievable !!! These results shows how recursive method is dangerous in this case.
n = 43 => my program not even stopping , even after 5 minutes .
Let us look on iterative method
long int fibonacciIteration(int n) {
int x = 0, y = 1, z = 1;
for (int i = 0; i < n; i++) {
x = y;
y = z;
z = x + y;
}
return x;
}
This method will return , fibonacci value within few seconds even if input n = 100 .
Conclusion is , selecting between iterative and recursive methods should be decided based on the problem statement, the problem looks simple with simple inputs, but analysing the problem with bigger inputs will actually shows the big picture .
Update: Complexity of recursive Fibonacci –
The recursive equation for this algorithm is T(n)=T(n−1)+T(n−2)+Θ(1)
For this it will be T(n)=Θ(ϕn)
where ϕ is the golden ratio (ϕ=(1+5√) / 2).
I strongly recommend to read Introduction to Algorithms 3rd edition : Purchase in FlipKart
Memory is one of the important resource , we can say its a crucial resource in computers. In a limited amount of memory an operating system tries to satisfy all the applications and the need of memory.
Let us try to understand how a memory looks – the theory and an example simple program to understand the concept in a better way.
Memory –

Understanding Of Memory
When we say a memory is allocated for an instance ! How exactly you visualise the memory and allocation ?
A memory is array of smallest unit of space which is nothing but a byte of space location. If a variable holds an integer, float or any type of data, it occupies certain set of such memory locations. Typically it looks like below.

In the above memory structure we can see how data is stored in memory.
The String “XYZ” , the number 15 , it looks like at location 12, number 15 is stored, starting from location 21, string XYZ is stored.
If I dig into the depth of it, every thing in computers will be converted into binary , so ‘X’ will be converted into binary which occupies 8 bits , similarly each character will be converted to its ASCII and the ASCII value will be converted to binary ( Ref – http://sticksandstones.kstrom.com/appen.html )
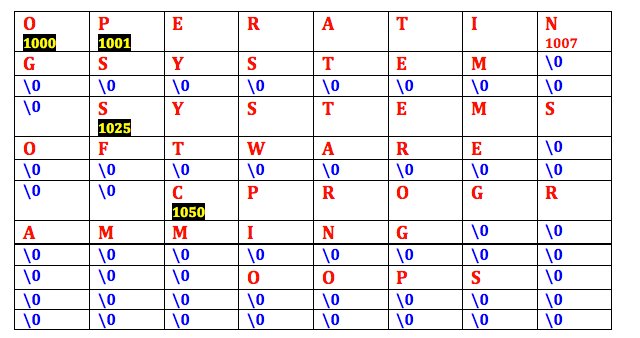
Let us consider one example and try to fill the memory locations
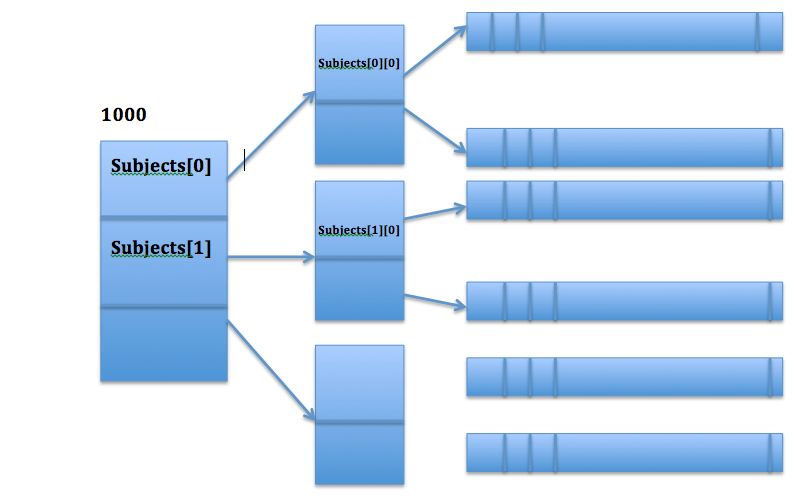
char subjects[3][2][25] ;
The above character multidimensional array will holds 2 subjects of 3 semesters each of length 25 characters.
subjects[0] -> will give you 2 subjects of first sem, each subject of 25 characters.
subjects[1] -> will give you 2 subjects of second sem, each subject of 25 characters.
If I assign the subjects to this array , the subject names in memory looks like below
For better understanding just check the below diagram of memory layout
Let us try an interesting example , a simple but an interesting analysis at the end. Let me start with a requirement by taking an example .
Assume that you are getting ‘ N ‘ number of strings from an xml file , where ‘ N ‘ is really huge. Each string is again having too many characters. A library is being used to parse the strings from the xml file, library will return the strings one by one.
The library returns string and the length of the string in a callback method, our program has to copy the string to keep a copy of it.
Let me write a simple code for this , to make the code simple for better understanding I will avoid library usage and all other stuff. Just let us focus of core problem , that is copying ‘ N ‘ strings.
int main(){
getStrings();
return 1;
}
void getStrings(){
int numberOfCharacters = 2014; // this length will be returned by Library after parsing xml file
char *string1 = (char*)malloc(numberOfCharacters); // to hold string
strcpy(string1,"This string we will get from library, for this example we are hard coding it");
char *string2 = (char*)malloc(numberOfCharacters); // to hold string
strcpy(string2,string1); // have a copy of string returned by library .
}
The above problem looks very simple, but the last strcpy() call will become costly for you since number of strings are too big.
How strcpy is costly ?
strcpy typically looks like below –
char* strcpy(char * string1, const char * string2){
char * originalStringPointer = string1;
while(*string2 != '\0'){
*string1++ = *string2++;
}
*string1 = '\0';
return originalStringPointer;
}
So behind the screen for every string copy ( for all your N strings, where N is too big ) , strcpy method iterates each character and copies .
Let us take one example and analyse this –
Analysis I –
If I have 100 strings all of same length say 10
then the number of times the loop in strcpy runs is
100 * 10 = 1000 times, this doesn’t make much difference .
Analysis II –
Let us take bigger value ,
If I have 3000 strings of length 100 each
then your loop in strcpy runs 3000 * 100 = 3,00,000 times
3,00,000 times is big, also we assumes all strings are of same size and that is just 100, but in realworld example that might be different again.
So in such a scenario your strcpy becomes very costly for you, your application performs really bad that too if you didn’t handle this case properly. If by chance you are reading all the strings during the app launch, your application takes several seconds to show the first screen.
A clever programmer finds a better way to achieve this with better way.
Better approach for better performance –
If you observe the problem statement, just notice that we have a string and its length both. so instead of using strcpy we can go for memcpy which actually just transfers chunk of data from one location to another location rather than copying it character by character.
so just replacing strcpy() by memcpy() avoids 3,00,000 loop executions in your second analysis .
your getStrings method looks like below now
void getStrings(){
int numberOfCharacters = 2014; // this length will be returned by Library after parsing xml file
char *string1 = (char*)malloc(numberOfCharacters); // to hold string
strcpy(string1,"This string we will get from library, for this example we are hard coding it");
char *string2 = (char*)malloc(numberOfCharacters); // to hold string
memcpy(string2,string1,numberOfCharacters); // have a copy with memcpy.
}
It is always a very good practice to find best possible way to do something, even a one line code which runs hundreds, thousands of times will become bottleneck.
This article is neither to judge quality of education nor to conclude on any plans or steps that have been taken by Government of India(GOI) to improve the literacy rate in the country.
The purpose of this article is just to provide certain facts and I would like to leave analysis of these facts to reader. Report on your analysis is welcomed through comments; do share your thoughts related to this article. All the data is collected from the reports which have been published by Government of India for public domain.
India is struggling with many issues, issues with respect to caste, religion, politics, languages , the mindset of people across the country varies a lot with respect to all the above factors. Despite of being such a diverse society, I would say India has achieved and reached many milestones in every sector. Considering education sector for this article, let us see what the report says.
Find out best realtime examples, interesting facts on concepts and all the formulas. The best mobile application for 10+ students (PUC I and II year students)
https://play.google.com/store/apps/details?id=com.dhi.educcesspu&hl=en

Achievements during 11th Five-year plan period
The result of 2011 census reveals that despite an impressive decadal increase of 9.2 percent points in literacy, national literacy levels have risen to no more than 74.0 percent (from 64.8 percent in 2001) Only 15 States/Union Territories, namely Kerala, Lakshadweep, Mizoram, Tripura, Goa, Daman & Diu, Puducherry, Chandigarh, Delhi, Andaman & Nicobar Islands, Himachal Pradesh, Maharashtra, Sikkim, Tamil Nadu and Nagaland could achieve 80 percent or above literacy rate.
The 2011 Census has shown that female literacy has increased much more than male literacy. While male literacy rate increased by 6.86 percent 279 points from 75.26 percent in 2001 to 82.14 in 2011, the female literacy increased by 11.79 percent points from 53.67 to 65.46 percent during the same period. Thus, by the end of the 11th Five Year Plan in 2012, the three Plan Targets would not have been achieved: overall literacy rate being short by five percent points.
Increase in literacy between 2001-2011 at National level:
There has been a substantial progress in literacy with the planned intervention and sustained effort from 64.83 per cent in 2001 to 74.04 per cent in 2011, an increase of 9.21 percentage points.

Sakshar Bharat
The Prime Minister launched Saakshar Bharat, a centrally sponsored scheme of Department of School Education and Literacy (DSEL), Ministry of Human Resource Development (MHRD), Government of India (GOI), on the International Literacy Day, 8th September, 2009.
Despite significant accomplishments of the Mission, illiteracy continues to be an area of national concern. 2001 census had revealed that there were still 259.52 million illiterate adults (in the age group of15 +) in the country.
Fund utilization and capacity building to achieve the milestone in education
During the financial year 2011-12, a total amount of Rs.488.50 crores was provided for Sakshar Bharat programme as Central share. An amount of Rs.429 crores was released till December 2011 to State Level Mission Authorities (SLMAs). A total of 1098.33 crores was released by NLMA to SLMAs during the last three years.
Government is keep trying and funding to increase the literacy rate within the country, in this process government has moved from SSA(Sarva Shiksha Abhiyan) Program to RTE ( Right to Education ).
RTE-SSA Financial Allocation
The Governmentn of India approved an outlay of Rs 71,000 crore for SSA in the 11th Five year plan. Considering the increased requirements, ,the Government of India approved an outlay Rs 2,31,233 crore for the combined RTE-SSA programme. This increased outlay was for a five year period from 2010-11 to 2014-15 to be shared between the Center and the State on a 65:35 ratio (90:10 for North Eastern States). The Finance Ministry allotted Rs 25,555 crore for the RTE-SSA programme for 2012-13. Just check the report chart below, government has spent 19,103,22cr upto January 2012.

Considering all the facts, percentile of literacy between 2001 – 20011, a 10 year period, the amount of money spent on it, the results may not be satisfactory, the reason is that focusing only on spending and opening schools doesn’t give the expected result, but focusing and executing the program towards quality education does bring the change. The path towards achieving really quality education is not an easy, more and more educated people has to come front to bring the change, it is not just the effort of government.
http://knowledge-cess.com/pythagoras-theorem-explained-mathemagic-with-bawa/
Sources of data
http://mhrd.gov.in/sites/upload_files/mhrd/files/RPE_2011-12.pdf
http://saaksharbharat.nic.in/saaksharbharat/homePage
An yearly report
http://mhrd.gov.in/documents/term/140
The most important step in any big application development life cycle is database design, If it requires any data storage. We have come across many developers who will never think much before finalising the database design. Some people will simply add fields into the table , some people simply define the data type without considering the type of data stored in real time. Let’s take a simple example and do analysis which shows big picture of database design importance with small set of data.
Consider the following example , a database designed for a simple requirement and then the analysis of the same.
Example – Requirement
Design a database for a web application where registered users will post articles. Any one can post any article, each article might fall under some category, A Category is again defined under a department and a stream. There will be Maximum 100 departments and 100 streams in the system.
For example , an article on “ Analysis of computer simulated data on wheels of a plane “, this article might fall under “Aerospace” Department, Physics stream .
Another article on “ Calculation of Voltage variations within the cooling system “ ,this article might fall under “Aerospace” Department , Electrical stream.
If we consider the above requirement and two examples , the following design sounds good – ( Note the database designed here is simple and just taken for simple analysis )

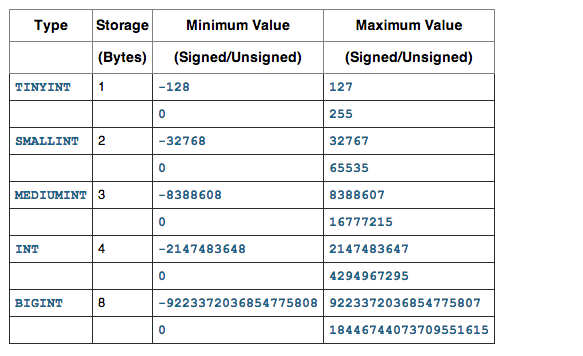
Considering the above design, and observe the department Id and Stream id fields in respective tables are defined as INT , The values of these two fields will never go beyond 100 as per the requirement. The first mistake is the datatype defined INT is not right. It can be declared as TINYINT(1) which holds value upto +127 , since both department id and stream id are declared as INT , extra 3 bytes is wasted for each record, because INT takes 4 bytes, and TINYINT takes 1 byte memory.
Let us analyse this scenario with simple real time example –
Analysis I –
If by chance each table ( department and stream ) holds 100 rows , then considering above storage details of each data type , for each row 3 bytes is wasted and hence if there are 100 records , for each table 300 bytes of data wasted.
So overall 600 bytes wasted from these two tables for just 100 records. This doesn’t make any difference because it is just a matter of few hundred bytes.
But If I change the above ArticePost table as follows ( that kind of mistakes usually happens when the database is bigger which will be having 100+ tables , since here only few tables are there then there is very less chance of such mistakes ).
Analysis II –
Modified ArticlePost table

For a quick access if I put both department id and stream id in ArticlePost table itself , the things will go worse !
Now consider 100 articles for each department and for each stream then total number of rows in ArticlePost = 10 * 100 * 100 = 100,000 articles, this is a simple math total ArticlePosts = (Articles for one dept/stream) * number of dept * number of streams
If we consider 100,000 number of rows in articles then the things will be worse ! For each row 600 bytes of memory waste as per Analysis I , so now for 100,000 rows how much memory waste ?
100,000 * 600 = 600,00,000 bytes = 57.220 MB memory wasted.
In real time , 100,000 of rows is not a big one , We should consider one thing very seriously here , 57.220 MB memory waste just because of two extra fields in a table and with improper usage of datatype .
Have a look on Data types and storage capacity from Mysql official documentation
Update –
Just observe how the data types in RDBMS are , INT(4) , INT(10), VARCHAR(25)
in general INT(N) , where N decides how much space it should consume ?.
Remember what we studied in C ? Can we relate this to C bit fields concept ?
Assume that I wanted to hold a status of the request in ma C program written for managing a government office complaint management system.
struct complaintStatus{
int isComplaintRaised;
int isComplainReceived;
int isComplaintResolved;
} status;
Since We are holding only status , it not required to have an int of 4 bytes ! only one byte is sufficient to hold either 0 or 1 , where 0 indicates NO , 1 indicates YES.
Let me modify the above Struct
struct complaintStatus{
int isComplaintRaised : 1;
int isComplainReceived : 1;
int isComplaintResolved : 1;
} status;
By above structure your compiler will restrict the amount of memory used by status .
Apple is awesome 🙂 , they always look towards something new ! Objective C is pretty old , yeah its 20+ years old now, so Apple thought its time to change now, and we have Swift with us now.
All About Swift you should know
Swift is a multi-paradigm programming language developed by Apple for use with iOS and OS X. Designed to replace Objective C, work began on Swift in 2010 and the first mobile app was debuted in June 2014 at the Worldwide Developers Conference. Despite its goal of replacing Objective C, Swift is capable of working flawlessly alongside the more dated Objective C language while using the Cocoa and Cocoa Touch frameworks. Swift adopts safe programming patterns and adds modern features to make programming easier, modern, powerful, expressive, and flexible.
Apple laid the foundation for Swift by advancing its existing compiler, debugger, and framework infrastructure. Memory management was simplified with Automatic Reference Counting (ARC). The framework stack, built on the solid base of Foundation and Cocoa, has been modernized and standardized throughout. Objective-C itself has evolved to support blocks, collection literals, and modules, enabling framework adoption of modern language technologies without disruption. With this groundwork, they introduce a new language Swift for the future of Apple software development.
It is the first industrial-quality systems programming language that is as expressive and enjoyable as a scripting language. It supports playgrounds, an innovative feature that allows programmers to experiment with Swift code and see the results immediately, without the overhead of building and running an app.
What are the requirements?
How is Swift Efficient?
Fast : Swift was built to be fast. Compiles and optimizes with the advanced code analysis in LLVM compiler included in Xcode 6 beta, and uses the Objective-C runtime, allowing Objective-C, Objective-C++ and Swift code to run within a single program.
This creates high-performance apps by transforming Swift code is into optimized native code, in turn to get the most out of modern Mac, iPhone, and iPad hardware.
Complete platform : It provides object-oriented features such as classes, protocols, and generics, giving Cocoa and Cocoa Touch developers the performance and power they demand from the frameworks with swift.
Safe by design : Eliminate huge categories of bugs, crashes, and security holes. Swift pairs increased type safety with type inference, restricts direct access to pointers, and automatically manages memory using ARC, making it easy for you to use Swift and create secure, stable software. Other language safety related features include mandatory variables initialization, automatic bounds checking to prevent overflows, conditionals break by default, and elimination of pointers to direct memory by default.
Modern : Write, debug, and maintain less code, with an easy to write and read syntax, and no headers to maintain. Swift includes optionals, generics, closures, tuples, and other modern language features. Inspired by and improving upon Objective-C, Swift code feels natural to read and write.
Interactive: Use Swift interactively to experiment with your ideas and see instant results.
Unified : A complete replacement for both the C and Objective-C languages. Swift provides full object-oriented features, and includes low-level language primitives such as types, flow control, and operators
How Swift works?
let constantValue = 88
var myVariable = 44
myVariable = 63
let integerConstant = 65
let doubleConstant = 65.0
let explicitDoubleConstant: Double = 70
let widthString = "The width is "
let widthValue = 94
let widthLabel = widthString + String(widthValue)
let apples = 3
let oranges = 5
let appleSummary = "I have \(apples) apples."
let fruitSummary = "I have \(apples + oranges) pieces of fruit."
Swift provides two collection types, known as arrays and dictionaries, for storing collections of values. Arrays store ordered lists of values of the same type. Dictionaries store unordered collections of values of the same type, which can be referenced and looked up through a unique identifier (also known as a key).
Create arrays and dictionaries using brackets ([]), and access their elements by writing the index or key in brackets.
The example below creates an array called shoppingList to store String values. The shoppingList variable is declared as “an array of String values”, written as String[].
var shoppingList: String[] = ["Eggs", "Milk"]
// shoppingList has been initialized with two initial items
To find out the number of items in an array, check its read-only count property,
println("The shopping list contains \(shoppingList.count) items.")
// prints “The shopping list contains 2 items.”
Use the Boolean isEmpty property as a shortcut for checking whether the count property is equal to 0:
if shoppingList.isEmpty {
println(“The shopping list is empty.”)
} else {
println(“The shopping list is not empty.”)
}
// prints “The shopping list is not empty.”
You can add a new item to the end of an array by calling the array’s append method:
shoppingList.append("Flour")
// shoppingList now contains 3 items, and someone is making pancakes
Alternatively, add a new item to the end of an array with the addition assignment operator (+=):
shoppingList += "Baking Powder"
// shoppingList now contains 4 items
You can also append an array of compatible items with the addition assignment operator (+=):
shoppingList += ["Chocolate Spread", "Cheese", "Butter"]
// shoppingList now contains 7 items
Retrieve a value from the array by using subscript syntax, passing the index of the value you want to retrieve within square brackets immediately after the name of the array:
var firstItem = shoppingList[0]
// firstItem is equal to “Eggs”
Note that the first item in the array has an index of 0, not 1. Arrays in Swift are always zero-indexed.
You can use subscript syntax to change an existing value at a given index:
shoppingList[0] = "Six eggs"
// the first item in the list is now equal to “Six eggs” rather than “Eggs”
You can also use subscript syntax to change a range of values at once, even if the replacement set of values has a different length than the range you are replacing. The following example replaces “Chocolate Spread”, “Cheese”, and “Butter” with “Bananas” and “Apples”:
shoppingList[4...6] = ["Bananas", "Apples"]
// shoppingList now contains 6 items
To insert an item into the array at a specified index, call the array’s insert(atIndex:) method:
shoppingList.insert("Maple Syrup", atIndex: 0)
// shoppingList now contains 7 items
// “Maple Syrup” is now the first item in the list
Remove an item from the array with the removeAtIndex method. This method removes the item at the specified index and returns the removed item (although you can ignore the returned value if you do not need it):
let mapleSyrup = shoppingList.removeAtIndex(0)
// the item that was at index 0 has just been removed
// shoppingList now contains 6 items, and no Maple Syrup
// the mapleSyrup constant is now equal to the removed “Maple Syrup” string
Iterating Over an Array
You can iterate over the entire set of values in an array with the for-in loop:
for iteminshoppingList {
println(item)
}
If you need the integer index of each item as well as its value, use the global enumerate function to iterate over the array instead. The enumerate function returns a tuple for each item in the array composed of the index and the value for that item. You can decompose the tuple into temporary constants or variables as part of the iteration:
for (index, value) inenumerate(shoppingList) {
println(“Item \(index + 1): \(value)”)
}// Item 1: Six eggs
A dictionary is a container that stores multiple values of the same type. Each value is associated with a unique key, which acts as an identifier for that value within the dictionary. Unlike items in an array, items in a dictionary do not have a specified order. You use a dictionary when you need to look up values based on their identifier
Swift’s dictionary type is written as Dictionary<KeyType, ValueType>,where KeyType is the type of value that can be used as a dictionary key, and ValueType is the type of value that the dictionary stores for those keys.
The only restriction is that KeyType must be hashable—that is, it must provide a way to make itself uniquely representable. All of Swift’s basic types (such as String, Int, Double, and Bool) are hashable by default, and all of these types can be used as the keys of a dictionary.
In a dictionary literal, the key and value in each key-value pair are separated by a colon. The key-value pairs are written as a list, separated by commas, surrounded by a pair of square brackets:
[key 1: value 1, key 2: value 2, key 3: value 3]
var airports: Dictionary<String, String> = [“TYO”: “Tokyo”, “DUB”: “Dublin”]
The airports dictionary is declared as having a type of Dictionary<String, String>, which means “aDictionary whose keys are of type String, and whose values are also of type String”.
You access and modify a dictionary through its methods and properties, or by using subscript syntax. As with an array, you can find out the number of items in a Dictionary by checking its read-only count property:
println("The dictionary of airports contains \(airports.count) items.")
// prints “The dictionary of airports contains 2 items.”
You can add a new item to a dictionary with subscript syntax. Use a new key of the appropriate type as the subscript index, and assign a new value of the appropriate type:
airports["LHR"] = "London"
// the airports dictionary now contains 3 items
You can also use subscript syntax to change the value associated with a particular key:
airports["LHR"] = "London Heathrow"
// the value for “LHR” has been changed to “London Heathrow”
As an alternative to subscripting, use a dictionary’s updateValue(forKey:) method to set or update the value for a particular key. Like the subscript examples above, the updateValue(forKey:) method sets a value for a key if none exists, or updates the value if that key already exists. Unlike a subscript, however, the updateValue(forKey:) method returns the old value after performing an update. This enables you to check whether or not an update took place.
The updateValue(forKey:) method returns an optional value of the dictionary’s value type. For a dictionary that stores String values, for example, the method returns a value of type String?, or “optional String”. This optional value contains the old value for that key if one existed before the update, or nil if no value existed:
if letoldValue = airports.updateValue("Dublin International", forKey: "DUB") {
println(“The old value for DUB was \(oldValue).”)
}
// prints “The old value for DUB was Dublin.”
You can use subscript syntax to remove a key-value pair from a dictionary by assigning a value of nil for that key:
airports["APL"] = "Apple International"
// “Apple International” is not the real airport for APL, so delete it
airports[“APL”] = nil
// APL has now been removed from the dictionary
Alternatively, remove a key-value pair from a dictionary with the removeValueForKey method. This method removes the key-value pair if it exists and returns the removed value, or returns nil if no value existed:
if letremovedValue = airports.removeValueForKey("DUB") {
println(“The removed airport’s name is \(removedValue).”)
} else {
println(“The airports dictionary does not contain a value for DUB.”)
}
// prints “The removed airport’s name is Dublin International.”
Iterating Over a Dictionary
You can iterate over the key-value pairs in a dictionary with a for-in loop. Each item in the dictionary is returned as a (key, value) tuple, and you can decompose the tuple’s members into temporary constants or variables as part of the iteration:
for (airportCode, airportName) inairports {
println(“\(airportCode): \(airportName)”)
}
// TYO: Tokyo
// LHR: London Heathrow
For more about the for-in loop, see For Loops.
You can also retrieve an iteratable collection of a dictionary’s keys or values by accessing its keys and values properties:
for airportCodeinairports.keys {
println(“Airport code: \(airportCode)”)
}
// Airport code: TYO
// Airport code: LHR
for airportNameinairports.values {
println(“Airport name: \(airportName)”)
}
// Airport name: Tokyo
// Airport name: London Heathrow
let emptyArray = String[]()
let emptyDictionary = Dictionary<String, Float>()
shoppingList = [] // Went shopping and bought everything.


{kind=link}